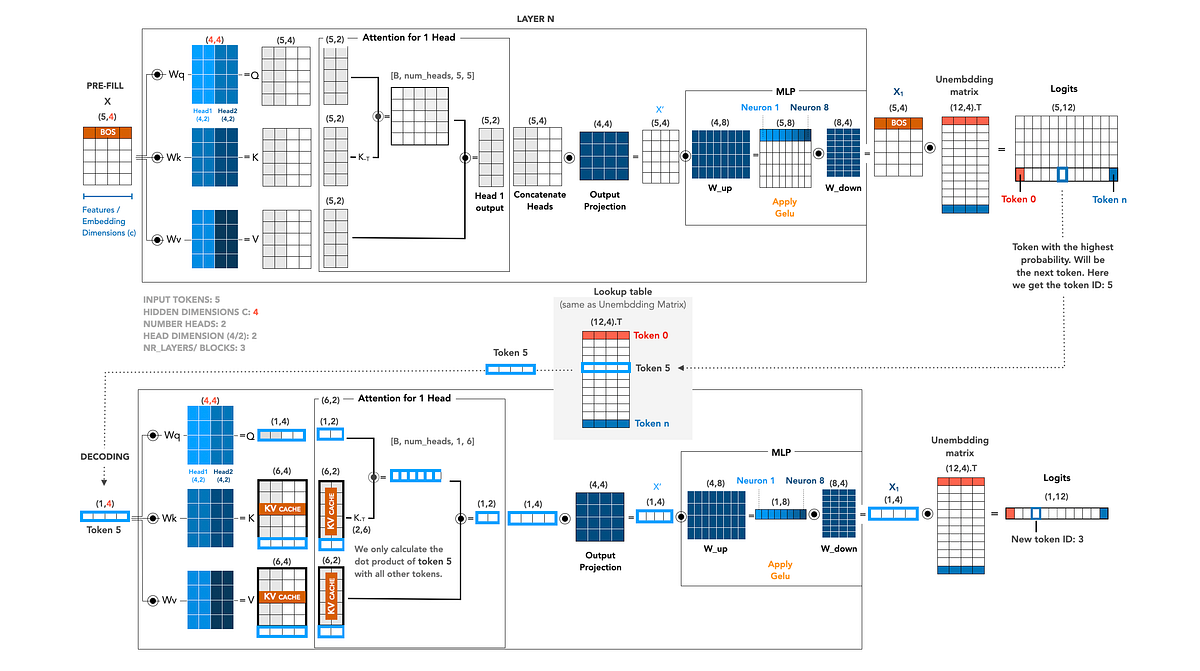
Step-by-step walkthrough of prefill vs. decode passes in transformer inference, showing exactly how KV cache cuts per-token compute from quadratic to roughly constant.
Key Takeaways
During prefill, the full prompt runs one parallel forward pass; K and V tensors (shape: seq_len x hidden_dim) are stored per layer, everything else discarded.
Decode mode feeds one token at a time; new K/V rows are appended to the cache, so attention reads (6, 2) keys while projections operate on a single (1, 4) row.
Without KV cache, generating N tokens requires redoing prefill N times, making cost quadratic; with it, each decode step costs roughly O(1) compute plus a cheap attention sum.
The unembedding matrix is typically the input embedding table transposed, projecting final hidden states back to vocab logits (shape: seq_len x vocab_size).
Residual connections let each decoder block add to, not overwrite, the hidden state, keeping gradients stable across deep stacks.