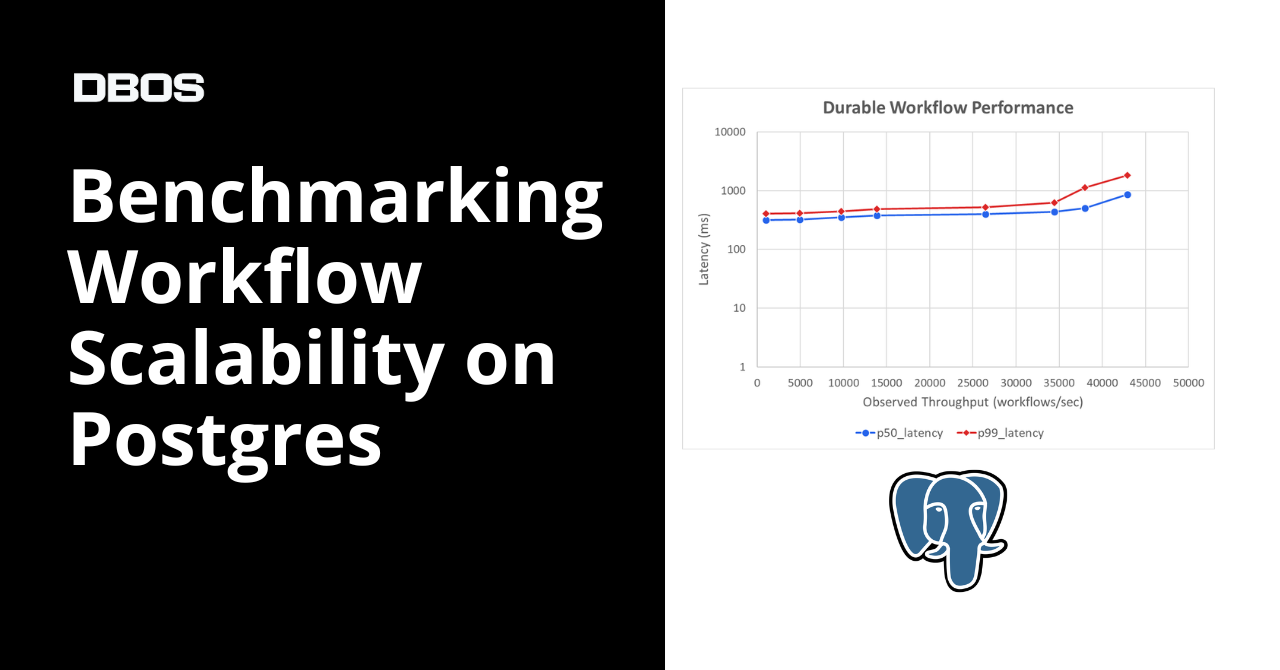
DBOS benchmarks a single RDS db.m7i.24xlarge Postgres instance and finds it can sustain 144K writes/sec or 43K durable workflows/sec.
Key Takeaways
Raw Postgres write ceiling on a 96-vCPU, 384GB RAM RDS instance with 120K IOPS: 144K inserts/sec, bottlenecked by WAL flush via group commit.
DBOS durable workflows (2 writes each) hit 43K workflows/sec; WAL lock contention, not CPU or IOPS, is the limiting factor.
Postgres-backed queue throughput drops to 12.1K workflows/sec single-queue due to row-level lock contention at queue head; partitioning across multiple queues recovers up to 30.6K/sec.
SKIP LOCKED helps but does not eliminate dequeue contention; Python client count amplifies the problem vs. faster runtimes like Go.
Sharding across multiple Postgres servers is the recommended path beyond single-node limits; no managed multi-master solution is discussed.
Hacker News Comment Review
Commenters challenge the 144K headline: at that concurrency level p50 write latency spikes from ~10ms to ~1s, meaning the server is saturated and the number is not operationally meaningful for OLTP.
Several engineers note the benchmark omits long-term Postgres health concerns: index fragmentation, dead tuple accumulation, and VACUUM behavior under sustained write load are absent from the analysis.
A recurring theme is that Postgres does scale, but requires undocumented tuning lore (checkpoint settings, WAL configuration, autovacuum) that trips up teams who assume default settings hold at high throughput.
Notable Comments
@ahachete: “p50 spikes from 10ms to 1s” at 120K writes/sec – calls 144K figure “misleading at best, essentially false” for production OLTP.
@sp1982: argues write QPS alone is the wrong metric; index fragmentation and dead tuple growth are the real long-term constraints.
@oa335: points to Postgres WAL configuration docs as a lever to push throughput further beyond what the benchmark tested.